|
此版本仍在开发中,尚未被视为稳定版。为了获取最新的快照版本,请使用Spring AI 1.1.3! |
使用 LLM 作为评判者的 LLM 响应评估
评估大型语言模型(LLM)输出的挑战对于众所周知的非确定性人工智能应用至关重要,尤其是在这些模型进入生产环境时。 传统的指标,如ROUGE和BLEU,在评估现代LLM生成的细微、上下文相关的回复时显得力不从心。 人工评估虽然准确,但成本高昂、效率低下且难以扩展。
LLM-as-a-Judge 是一种强大的技术,它利用 LLM 本身来评估 AI 生成内容的质量。 研究 表明,复杂的判断模型可以与人类判断保持高达 85% 的一致性,这实际上高于人与人之间的协议(81%)。
Spring AI 的 递归顾问 提供了一个优雅的框架,用于实现 LLM 作为裁判的模式,使您能够构建具有自动化质量控制的自我改进 AI 系统。
| 在 evaluation-recursive-advisor-demo 中找到完整的示例实现。 |
理解LLM作为裁判
LLM-as-a-Judge 是一种评估方法,其中大型语言模型对其他模型或自身生成的输出质量进行评估。 与仅依赖人类评估者或传统自动化指标不同,LLM-as-a-Judge 利用大型语言模型根据预定义的标准对响应进行评分、分类或比较。
为什么它有效?评估从根本上来说比生成更容易。 当你使用LLM作为评判者时,你实际上是在让它执行一项更简单、更专注的任务(评估现有文本的特定属性),而不是在平衡多重约束的同时创作原创内容这一复杂任务。 一个恰当的类比是:批评比创作更容易。发现问题比预防问题更简单。
选择合适的法官模型
虽然像GPT-4和Claude这样的通用模型可以作为有效的评判者,但专门的LLM作为评判者的模型在评估任务中始终表现更优。 Judge Arena排行榜专门跟踪各类模型在评判任务中的表现。
使用递归顾问的实现
Spring AI 的 ChatClient 提供了一个流畅的 API,非常适合实现 LLM 作为裁判的模式。 它的 Advisors 系统 允许您以模块化、可重用的方式拦截、修改和增强 AI 交互。
The Recursive Advisors take this further by enabling looping patterns that are perfect for self-refining evaluation workflows:
public class MyRecursiveAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// Call the chain initially
ChatClientResponse response = chain.nextCall(request);
// Check if we need to retry based on evaluation
while (!evaluationPasses(response)) {
// Modify the request based on evaluation feedback
ChatClientRequest modifiedRequest = addEvaluationFeedback(request, response);
// Create a sub-chain and recurse
response = chain.copy(this).nextCall(modifiedRequest);
}
return response;
}
}我们将使用 Spring AI 的递归顾问实现一个体现 LLM 作为裁判模式的 SelfRefineEvaluationAdvisor。
该顾问会自动评估 AI 响应,并根据反馈驱动改进来重试失败的尝试:生成响应 → 评估质量 → 如有必要,根据反馈重试 → 重复此过程,直到达到质量阈值或达到重试限制。
自我优化评估顾问
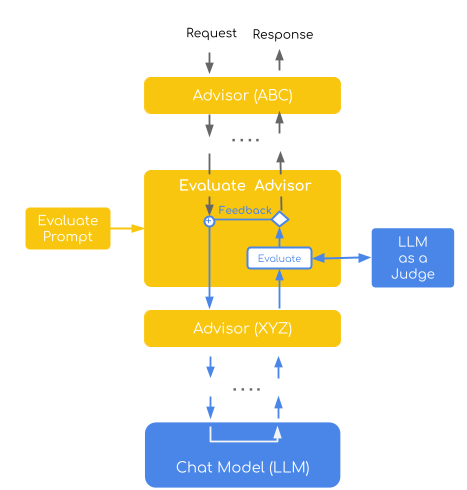
此实现展示了直接评估评估模式,其中裁判模型使用逐点评分系统(1-4分制)对单个回答进行评估。 它结合了自我优化策略,该策略通过将特定反馈纳入后续尝试中自动重试失败的评估,从而形成一个迭代改进循环。
该顾问体现了两个关键的“LLM作为裁判”概念:
-
逐点评估:每个回复都会根据预定义的标准获得单独的质量评分
-
自我完善:失败的响应会触发重试,并提供建设性的反馈以指导改进
(基于文章:使用LLM作为裁判进行自动化且多功能的评估)
public final class SelfRefineEvaluationAdvisor implements CallAdvisor {
private static final PromptTemplate DEFAULT_EVALUATION_PROMPT_TEMPLATE = new PromptTemplate(
"""
You will be given a user_question and assistant_answer couple.
Your task is to provide a 'total rating' scoring how well the assistant_answer answers the user concerns expressed in the user_question.
Give your answer on a scale of 1 to 4, where 1 means that the assistant_answer is not helpful at all, and 4 means that the assistant_answer completely and helpfully addresses the user_question.
Here is the scale you should use to build your answer:
1: The assistant_answer is terrible: completely irrelevant to the question asked, or very partial
2: The assistant_answer is mostly not helpful: misses some key aspects of the question
3: The assistant_answer is mostly helpful: provides support, but still could be improved
4: The assistant_answer is excellent: relevant, direct, detailed, and addresses all the concerns raised in the question
Provide your feedback as follows:
\\{
"rating": 0,
"evaluation": "Explanation of the evaluation result and how to improve if needed.",
"feedback": "Constructive and specific feedback on the assistant_answer."
\\}
Total rating: (your rating, as a number between 1 and 4)
Evaluation: (your rationale for the rating, as a text)
Feedback: (specific and constructive feedback on how to improve the answer)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here are the question and answer.
Question: {question}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Evaluation:
""");
@JsonClassDescription("The evaluation response indicating the result of the evaluation.")
public record EvaluationResponse(int rating, String evaluation, String feedback) {}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
var request = chatClientRequest;
ChatClientResponse response;
// Improved loop structure with better attempt counting and clearer logic
for (int attempt = 1; attempt <= maxRepeatAttempts + 1; attempt++) {
// Make the inner call (e.g., to the evaluation LLM model)
response = callAdvisorChain.copy(this).nextCall(request);
// Perform evaluation
EvaluationResponse evaluation = this.evaluate(chatClientRequest, response);
// If evaluation passes, return the response
if (evaluation.rating() >= this.successRating) {
logger.info("Evaluation passed on attempt {}, evaluation: {}", attempt, evaluation);
return response;
}
// If this is the last attempt, return the response regardless
if (attempt > maxRepeatAttempts) {
logger.warn(
"Maximum attempts ({}) reached. Returning last response despite failed evaluation. Use the following feedback to improve: {}",
maxRepeatAttempts, evaluation.feedback());
return response;
}
// Retry with evaluation feedback
logger.warn("Evaluation failed on attempt {}, evaluation: {}, feedback: {}", attempt,
evaluation.evaluation(), evaluation.feedback());
request = this.addEvaluationFeedback(chatClientRequest, evaluation);
}
// This should never be reached due to the loop logic above
throw new IllegalStateException("Unexpected loop exit in adviseCall");
}
/**
* Performs the evaluation using the LLM-as-a-Judge and returns the result.
*/
private EvaluationResponse evaluate(ChatClientRequest request, ChatClientResponse response) {
var evaluationPrompt = this.evaluationPromptTemplate.render(
Map.of("question", this.getPromptQuestion(request), "answer", this.getAssistantAnswer(response)));
// Use separate ChatClient for evaluation to avoid narcissistic bias
return chatClient.prompt(evaluationPrompt).call().entity(EvaluationResponse.class);
}
/**
* Creates a new request with evaluation feedback for retry.
*/
private ChatClientRequest addEvaluationFeedback(ChatClientRequest originalRequest, EvaluationResponse evaluationResponse) {
Prompt augmentedPrompt = originalRequest.prompt()
.augmentUserMessage(userMessage -> userMessage.mutate().text(String.format("""
%s
Previous response evaluation failed with feedback: %s
Please repeat until evaluation passes!
""", userMessage.getText(), evaluationResponse.feedback())).build());
return originalRequest.mutate().prompt(augmentedPrompt).build();
}
}关键实现特性
递归模式实现
顾问使用callAdvisorChain.copy(this).nextCall(request)来创建用于递归调用的子链,从而在保持正确顾问顺序的同时实现多轮评估。
结构化评估输出
使用 Spring AI 的 结构化输出 功能,评估结果会被解析为一条包含评分(1-4)、评估理由以及具体改进建议的 EvaluationResponse 记录。
单独评估模型
使用专门的LLM作为评判模型(例如:avcodes/flowaicom-flow-judge:q4),并搭配不同的ChatClient实例,以减轻模型偏差。
设置spring.ai.chat.client.enabled=false以启用使用多个聊天模型。
反馈驱动的改进
失败的评估包含特定的反馈信息,这些信息会被纳入重试尝试中,从而使系统能够从评估失败中学习。
可配置的重试逻辑
支持在达到评估限制时进行可配置的最大尝试次数,并实现优雅降级。
完整示例
以下是将SelfRefineEvaluationAdvisor集成到完整的Spring AI应用程序中的方法:
@SpringBootApplication
public class EvaluationAdvisorDemoApplication {
@Bean
CommandLineRunner commandLineRunner(AnthropicChatModel anthropicChatModel, OllamaChatModel ollamaChatModel) {
return args -> {
ChatClient chatClient = ChatClient.builder(anthropicChatModel)
.defaultTools(new MyTools())
.defaultAdvisors(
SelfRefineEvaluationAdvisor.builder()
.chatClientBuilder(ChatClient.builder(ollamaChatModel)) // Separate model for evaluation
.maxRepeatAttempts(15)
.successRating(4)
.order(0)
.build(),
new MyLoggingAdvisor(2))
.build();
var answer = chatClient
.prompt("What is current weather in Paris?")
.call()
.content();
System.out.println(answer);
};
}
static class MyTools {
final int[] temperatures = {-125, 15, -255};
private final Random random = new Random();
@Tool(description = "Get the current weather for a given location")
public String weather(String location) {
int temperature = temperatures[random.nextInt(temperatures.length)];
System.out.println(">>> Tool Call responseTemp: " + temperature);
return "The current weather in " + location + " is sunny with a temperature of " + temperature + "°C.";
}
}
}此配置:
-
使用 Anthropic Claude 进行生成,使用 Ollama 进行评估(避免偏见)。
-
需要评分为4,并最多尝试15次重试。
-
包含一个天气工具,用于生成随机响应以触发评估。
-
The
weathertool generates invalid values in 2/3 of the cases
The SelfRefineEvaluationAdvisor (Order 0) evaluates response quality and retries with feedback if needed, followed by MyLoggingAdvisor (Order 2) which logs the final request/response for observability.
运行时,您将看到如下输出:
REQUEST: [{"role":"user","content":"What is current weather in Paris?"}]
>>> Tool Call responseTemp: -255
Evaluation failed on attempt 1, evaluation: The response contains unrealistic temperature data, feedback: The temperature of -255°C is physically impossible and indicates a data error.
>>> Tool Call responseTemp: 15
Evaluation passed on attempt 2, evaluation: Excellent response with realistic weather data
RESPONSE: The current weather in Paris is sunny with a temperature of 15°C.| 完整的可运行演示,包含配置示例、不同的模型组合和评估场景,可在 evaluation-recursive-advisor-demo 项目中获取。 |
最佳实践
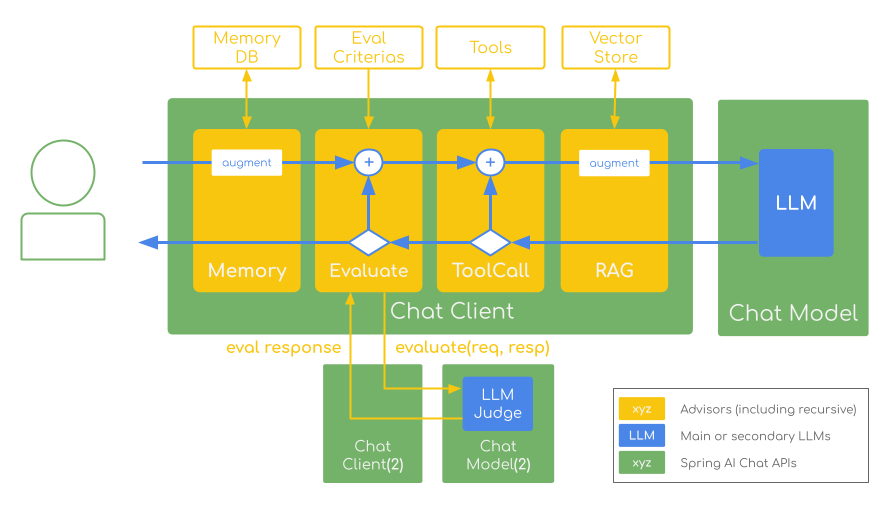
实施 LLM 作为裁判技术时的关键成功因素包括:
-
使用专用的判题模型以获得更好的性能(参见 判题竞技场排行榜)
-
通过独立的生成/评估模型缓解偏差
-
确保确定性结果(温度 = 0)
-
工程师提示带有整数比例和少样本示例
-
保持人工监督以应对高风险决策
|
递归顾问是 Spring AI 1.1.0-M4+ 中的一项全新实验性功能。 目前,它们仅支持非流式处理,需要谨慎安排顾问顺序,并且由于多次调用大语言模型,可能会增加成本。 请特别注意那些维护外部状态的内部通知器——它们可能需要额外的关注,以确保在多次迭代中保持正确性。 始终设置终止条件和重试限制,以防止出现无限循环。 |
参考资料
Spring AI 资源
LLM作为裁判的研究
-
法官竞技场排行榜 - 当前表现最佳的法官模型排名
-
使用MT-Bench和Chatbot Arena评估LLM作为裁判 - 介绍LLM作为裁判范式的奠基性论文